------Java培训、Android培训、iOS培训、.Net培训、期待与您交流! -------
第一讲 预处理指令
预处理指令的概述
- C语言在对源程序进行编译之前,会先对一些特殊的预处理指令作解释,比如之前使用的#include文件包含指令,产生一个新的源程序,这个过程称为编译预处理,之后再进行通常的编译
- 为了区分预处理指令和一般的C语句,所有预处理指令都以符号"#"开头,并且结尾不用分号
- 预处理指令可以出现在程序的任何位置,它的作用范围是从它出现的位置到文件尾。习惯上我们尽可能将预处理指令写在源程序开头,这种情况下,它的作用范围就是整个源程序文件
一、宏定义
1、不带参数的宏定义
1)、一般格式:#define 宏名 字符串
1 #define COUNT 4 //宏名一般用大写或者以k开头,变量名一般用小写
2)、作用
它的作用是在编译预处理时,将源程序中所有"宏名"替换成右边的"字符串",常用来定义常量。
#include// 源程序中所有的宏名PI在编译预处理的时候都会被3.14所代替 #define PI 3.14// 根据圆的半径计r算周长float girth(r) {return 2 * PI *r;} int main (){ float g = girth(2); printf("圆的周长为:%f", g); return 0; }
3)、使用注意
- 宏名一般用大写字母,以便与变量名区别开来,但用小写也没有语法错误
- 对程序中用双引号扩起来的字符串内的字符,不进行宏的替换操作。
- 在编译预处理用字符串替换宏名时,不作语法检查,只是简单的字符串替换
- 宏名的有效范围是从定义位置到文件结束。如果需要终止宏定义的作用域,可以用#undef命令
- 定义一个宏时可以引用已经定义的宏名
1 #include2 #define R 3.0 3 #define PI 3.14 4 #define L 2*PI*R //引用已经定义的宏名 5 6 #define COUNT 4 7 8 int main() 9 {10 char *name = "COUNT"; //双引号内的内容不会被替换11 12 printf("%s\n", name);13 14 15 #undef COUNT // 从这行开始,COUNT这个宏就失效16 17 int a = COUNT; //这行开始就会报错18 19 return 0;20 }21 #define COUNT 422 23 int main()24 {25 char *name = "COUNT"; //双引号内的内容不会被替换26 27 printf("%s\n", name);28 29 30 #undef COUNT // 从这行开始,COUNT这个宏就失效31 32 int a = COUNT; //这行开始就会报错33 34 return 0;35 }
2、带参数的宏定义
1)、一般格式:#define 宏名(参数列表) 字符串
#define sum(v1, v2) ((v1)+(v2)) // v1,v2 是宏的参数
2)、在编译预处理时,将源程序中所有宏名替换成字符串,并且将 字符串中的参数 用 宏名右边参数列表 中的参数替换
1 #include2 3 #define sum(v1, v2) ((v1)+(v2)) // 定义带参数的宏 4 5 int main() 6 { 7 8 9 int c = sum(2, 3) * sum(6, 4);10 11 printf("c is %d\n", c); //输出的结果是 5012 13 14 return 0;15 }
3)、带参数宏使用注意
- 宏名和参数列表之间不能有空格,否则空格后面的所有字符串都作为替换的字符串
- 带参数的宏在展开时,只作简单的字符和参数的替换,不进行任何计算操作
- 计算结果最好用括号括起来
3、与函数的区别
从整个使用过程可以发现,带参数的宏定义,在源程序中出现的形式与函数很像。但是两者是有本质区别的:
- 宏定义不涉及存储空间的分配、参数类型匹配、参数传递、返回值问题
- 函数调用在程序运行时执行,而宏替换只在编译预处理阶段进行。所以带参数的宏比函数具有更高的执行效率
二、条件编译
1、条件编译概述
在很多情况下,我们希望程序的其中一部分代码只有在满足一定条件时才进行编译,否则不参与编译(只有参与编译的代码最终才能被执行),这就是条件编译。
2、一般格式
1 #if 条件12 ...code1...3 #elif 条件24 ...code2...5 #else6 ...code3...7 #endif
- 如果条件1成立,那么编译器就会把#if 与 #elif之间的code1代码编译进去(注意:是编译进去,不是执行,很平时用的if-else是不一样的)
- 如果条件1不成立、条件2成立,那么编译器就会把#elif 与 #else之间的code2代码编译进去
- 如果条件1、2都不成立,那么编译器就会把#else 与 #endif之间的code3编译进去
- 注意,条件编译结束后,要在最后面加一个#endif,不然后果很严重(自己思考一下后果)
- #if 和 #elif后面的条件一般是判断宏定义而不是判断变量,因为条件编译是在编译之前做的判断,宏定义也是编译之前定义的,而变量是在运行时才产生的、才有使用的意义
3、举例
1 #include2 3 // 只要写了#if,在最后面必须加上#endif 4 5 //#define A 10 6 7 int main() 8 { 9 10 #if (A == 10)11 printf("a是10\n"); //11行代码才会被编译,其他行代码不会编译12 #elif (A == 5)13 printf("a是5\n");14 #else15 printf("a其他值\n");16 #endif17 18 19 return 0;20 }
4、其他用法
1)、#if defined()和#if !defined()的用法
#if 和 #elif后面的条件不仅仅可以用来判断宏的值,还可以判断是否定义过某个宏。
1 #if defined(MAX) //判断是否定义过宏 MAX2 ...code... //如果定义过宏,就编译code这段代码3 #endif
条件也可以取反:
1 #if !defined(MAX) // 判断是否定义过宏MAX2 ...code... //如果没有定义过宏,就编译code这段代码3 #endif
2)、#ifdef和#ifndef的使用
* #ifdef的使用和#if defined()的用法基本一致
1 #ifdef(MAX) //判断是否定义过宏 MAX2 ...code... //如果定义过宏,就编译code这段代码3 #endif
* #ifndef又和#if !defined()的用法基本一致
1 #ifndef(MAX) // 判断是否定义过宏MAX2 ...code... //如果没有定义过宏,就编译code这段代码3 #endif
三、文件包含
1、概述
文件包含就是将一个文件的全部内容拷贝另一个文件中。如常用的#include <stdio.h> 头文件。
2、一般格式
1)#include <文件名>
直接到C语言库函数头文件所在的目录中寻找文件
2) #include "文件名"
系统会先在源程序当前目录下寻找,若找不到,再到操作系统的path路径中查找,最后才到C语言库函数头文件所在目录中查找
3、使用注意
#include指令允许嵌套包含,比如a.h包含b.h,b.h包含c.h,但是不允许递归包含,比如 a.h 包含 b.h,b.h 包含 a.h。
下面的做法是错误的
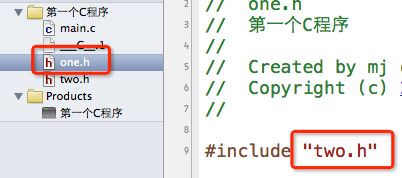

使用#include指令可能导致多次包含同一个头文件,降低编译效率
比如下面的情况:
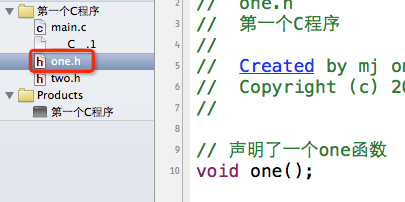
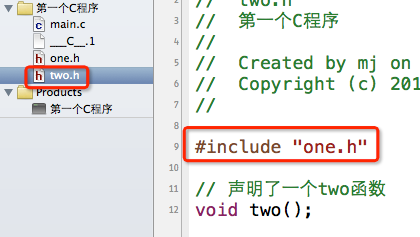
在one.h中声明了一个one函数;在two.h中包含了one.h,顺便声明了一个two函数。(这里就不写函数的实现了,也就是函数的定义)
假如我想在main.c中使用one和two两个函数,而且有时候我们并不一定知道two.h中包含了one.h,所以可能会这样做:
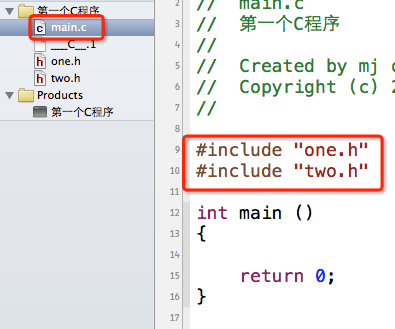
编译预处理之后main.c的代码是这样的:
1 void one();2 void one();3 void two();4 int main ()5 {6 7 return 0;8 9 }
第1行是由#include "one.h"导致的,第2、3行是由#include "two.h"导致的(因为two.h里面包含了one.h)。可以看出来,one函数被声明了2遍,根本就没有必要,这样会降低编译效率。
为了解决这种重复包含同一个头文件的问题,一般我们会这样写头文件内容:
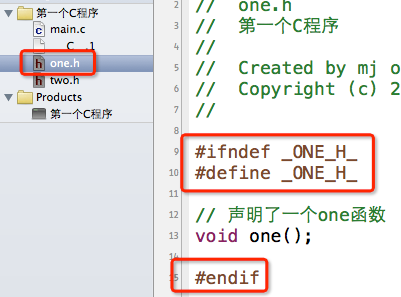

大致解释一下意思,就拿one.h为例:当我们第一次#include "one.h"时,因为没有定义_ONE_H_,所以第9行的条件成立,接着在第10行定义了_ONE_H_这个宏,然后在13行声明one函数,最后在15行结束条件编译。当第二次#include "one.h",因为之前已经定义过_ONE_H_这个宏,所以第9行的条件不成立,直接跳到第15行的#endif,结束条件编译。就是这么简单的3句代码,防止了one.h的内容被重复包含。
这样子的话,main.c中的:
#include "one.h"#include "two.h"
就变成了:
1 // #include "one.h" 2 #ifndef _ONE_H_ 3 #define _ONE_H_ 4 5 void one(); 6 7 #endif 8 9 // #include "two.h"10 #ifndef _TWO_H_11 #define _TWO_H_12 13 // #include "one.h"14 #ifndef _ONE_H_15 #define _ONE_H_16 17 void one();18 19 #endif20 21 void two();22 23 #endif
第2~第7行是#include "one.h"导致的,第10~第23行是#include "two.h"导致的。
//编译预处理之后就变为了: void one(); void two(); //这才是我们想要的结果
第二讲 static与extern的使用
一、static与extern对函数的作用
- 外部函数:如果在当前文件中定义的函数允许其他文件访问、调用,就称为外部函数。C语言规定,不允许有同名的外部函数。
- 内部函数:如果在当前文件中定义的函数不允许其他文件访问、调用,只能在内部使用,就称为内部函数。C语言规定不同的源文件可以有同名的内部函数,并且互不干扰。
1、extern与函数
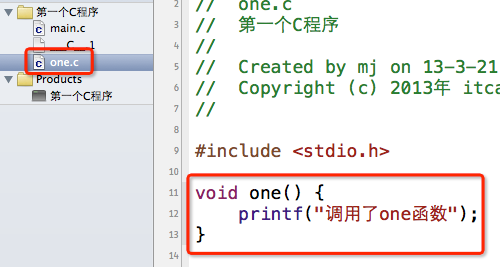
1).在one.c中定义一个one函数
如果你想让这个one函数可以被main.c访问,那么one函数就必须是外部函数。完整的定义是要加上extern关键字。

不过这个extern完全可以省略,默认情况下,所有的函数就是外部函数。我们可以简化一下:
2)、在main函数中调用one函数(需提前声明one函数)
想要把其他源文件中定义的外部函数拿过来声明,完整的做法,应该使用extern关键字,表示引用别人的"外部函数"

运行程序,从控制台输出可以发现 "one.c中定义的one函数" 已经被 "main.c的main函数" 成功调用了。
2、static与函数
1)、在one.c中定义一个内部函数
从上面的例子可以看出,one.c中定义的one函数是可以被其他源文件访问的。其实有时候,我们可能想定义一个"内部函数",也就是不想让其他文件访问本文件中定义的函数。这个非常简单,你只需要在定义函数的时候加个static关键字即可。
(我们就在上面例子的代码基础上进行修改)
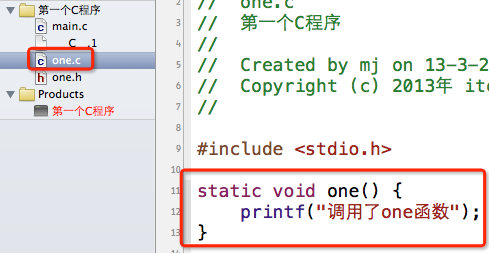
我在void one()的前面加了个static,代表one函数是个内部函数。
然后你会发现程序运行不起来了,在链接的时候就报错了。报错的原因很简单:我们在main.c中调用了one.c中定义的one函数,但是现在one.c的one函数是个"内部函数",不允许其他文件访问。
2)、声明内部函数
#includestatic void test(); //声明一个内部函数int main(int argc, const char * argv[]){ test(); return 0;} static void test() { //定义一个内部函数 printf("调用了test函数"); }
3、static、extern与函数的总结
1) static
* 在定义函数时,在函数的最左边加上static可以把该函数声明为内部函数(又叫静态函数),这样该函数就只能在其定义所在的文件中使用。如果在不同的文件中有同名的内部函数,则互不干扰。
* static也可以用来声明一个内部函数
2) extern
* 在定义函数时,如果在函数的最左边加上关键字extern,则表示此函数是外部函数,可供其他文件调用。C语言规定,如果在定义函数时省略extern,则隐含为外部函数。
* 在一个文件中要调用其他文件中的外部函数,则需要在当前文件中用extern声明该外部函数,然后就可以使用,这里的extern也可以省略。
二、static、extern对变量的作用
1、extern与变全局变量
默认情况下,一个函数不可以访问在它后面定义的全局变量
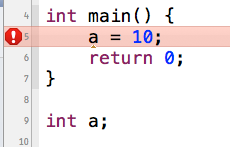
在第4行定义的main函数中尝试访问第9行定义的变量a,编译器直接报错了。
这个错误的话,有2种解决办法:
- 将变量a定义在main函数的前面,就不会报错

- 在main函数前面对变量a进行提前声明
也就是让main函数知道变量a的存在就行了,至于变量a定义在哪个位置,main函数不用管。
* 完整的变量声明需要用extern关键字
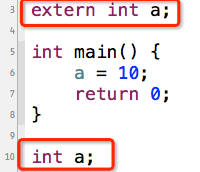
第3行是对变量a进行声明,第10行是定义变量a,再次强调,声明和定义是两码事。在第6行操作的就是第10行定义的变量a。
注意:你不能省略第10行的定义,只留下第3行的声明,因为extern是用来声明一个已经定义过的变量。
1)、重复定义同一个变量
- 其实,你也可以直接在main函数前面再定义一次a

看到这一幕,你可能很惊讶,但编译器是不会报错的。在这种情况下,第3行和第10行的变量a代表着同一个变量。
- 以此类推,如果我们写了无数遍全局变量int a;,它们代表的都是同一个变量。
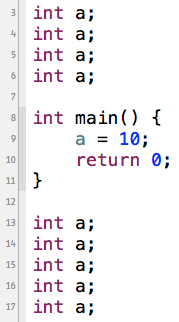 第3到第6行、第13到第17行的变量a都代表着同一个变量。
第3到第6行、第13到第17行的变量a都代表着同一个变量。
- 还要注意的一点是,我们也可以将全局变量a声明为局部变量后再使用!!!
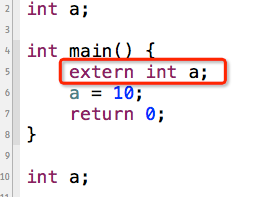
注意:第2、第5、第6、第10行都代表着同一个变量。其实,从第6行a的颜色(浅蓝色)都可以看出,这个a依然是个全局变量。
2、static与全局变量
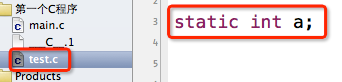
很多时候,我们并不想让源文件中的全局变量跟其他源文件共享,相当于私有的全局变量,那么你就得用static关键字来定义变量。
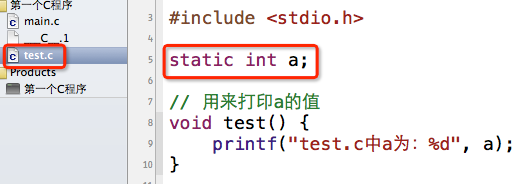
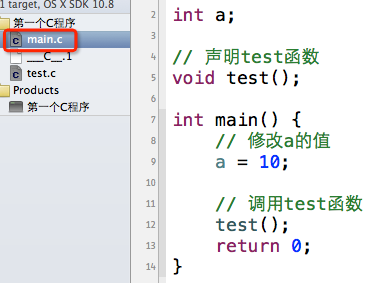
这样写完,test.c和main.c的变量a分别代表着不同的变量,它们是没有联系的、互不干扰的。也就是说,main.c无法访问test.c中的变量a,因此在main.c中将a修改为10后,test.c中的a依然为0。输出结果:
因为main.c已经没有权限访问test.c中的变量a了,所以下面的写法是错误的:
 和
和
extern是用来声明已经定义过而且能够访问的变量,虽然test.c中有定义过变量a,但是test.c中变量a的作用域是只限于test.c文件,main.c没有访问权限,所以main.c中的extern是没有用的。
3、static与局部变量
被关键字static修饰的变量(局部变量、全局变量)成为静态变量,静态变量是存储在静态内存中的,也就是不属于堆栈。
1#include2 3 int a; 4 5 void test() { 6 static int b = 0; //创建一个静态变量b 7 b++; 8 9 int c = 0;10 c++;11 12 printf("b=%d, c=%d \n", b, c);13 }14 15 int main() {16 int i;17 // 连续调用3次test函数18 for (i = 0; i<3; i++) {19 test();20 }21 22 return 0;23 }
* 第3行的变量a、第6行的变量b都是静态变量,第9行的变量c、第16行的变量i是自动变量。
* 因为第6行的变量b是静态变量,所以它只会被创建一次,而且生命周期会延续到程序结束。因为它只会创建一次,所以第6行代码只会执行一次,下次再调用test函数时,变量b的值不会被重新初始化为0。
* 注意:虽然第6行的变量b是静态变量,但是只改变了它的存储类型(即生命周期),并没有改变它的作用域,变量b还是只能在test函数内部使用。
* 我们在main函数中重复调用test函数3次,输出结果为:
第三讲 typedef
1、typedef使用简介
一般格式 :typedef 数据类型 别名;
1 typedef int MyInt; //给int 类型取个 MyInt别名 2 typedef MyInt MyInt2; //别名的基础上再起一个别名 3 void test() 4 { 5 int a; 6 MyInt i = 10; 7 MyInt2 c = 20; 8 9 MyInt b1, b2;10 11 printf("c is %d\n", c); //c的输出结果为 20 12 }
2、typedef与指针
1 typedef char * String ;2 3 void test2()4 {5 String name = "jack";6 7 printf("%s\n", name); //输出结果为 jack8 }
3、typedef与指向函数的指针
1#include2 3 // 定义一个sum函数,计算a跟b的和 4 int sum(int a, int b) { 5 int c = a + b; 6 printf("%d + %d = %d", a, b, c); 7 return c; 8 } 9 10 typedef int (*MySum)(int, int);11 12 int main(int argc, const char * argv[]) {13 // 定义一个指向sum函数的指针变量p14 MySum p = sum;15 16 // 利用指针变量p调用sum函数17 (*p)(4, 5);18 19 return 0;20 }
* 看第10行,意思是:给指向函数的指针类型,起了个别名叫MySum,被指向的函数接收2个int类型的参数,返回值为int类型。
* 在第14行直接用别名MySum定义一个指向sum函数的指针变量p。第17行的函数调用是一样的
4、typedef与结构体
1 //第一种方式 2 3 struct Student // 先定义一个结构体类型 4 { 5 int age; 6 }; 7 typedef struct Student MyStu; //结构体类型 取别名 8 9 10 /* 第二种方式 定义结构体类型的同时 取别名11 typedef struct Student12 {13 int age;14 } MyStu;15 */16 17 /*第三种方式 省略结构体类型名称18 typedef struct19 {20 int age;21 } MyStu;22 */
5、typedef与枚举类型
/* 第一种方式 先定义结构体类型enum Sex {Man, Woman};typedef enum Sex MySex; //再给结构体类型取别名*///第二种方式typedef enum Sex { //定义枚举类型的同时给枚举类型取别名 Man, Woman} MySex;/* 第三种方式typedef enum { //省略枚举类型名称 给枚举类型取别名 Man, Woman} MySex;*/
6、typedef与指向结构体的指针
typedef可以给指针、结构体起别名,当然也可以给指向结构体的指针起别名
#include// 定义一个结构体并起别名 typedef struct { float x;float y; } Point; typedef Point *PP;// 起别名int main() {Point point = { 10, 20};// 定义结构体变量PP p = &point; // 定义指针变量printf("x=%f,y=%f", p->x, p->y);// 利用指针变量访问结构体成员 return 0; }